
Introducción a los Algoritmos: Aprendizaje Automático
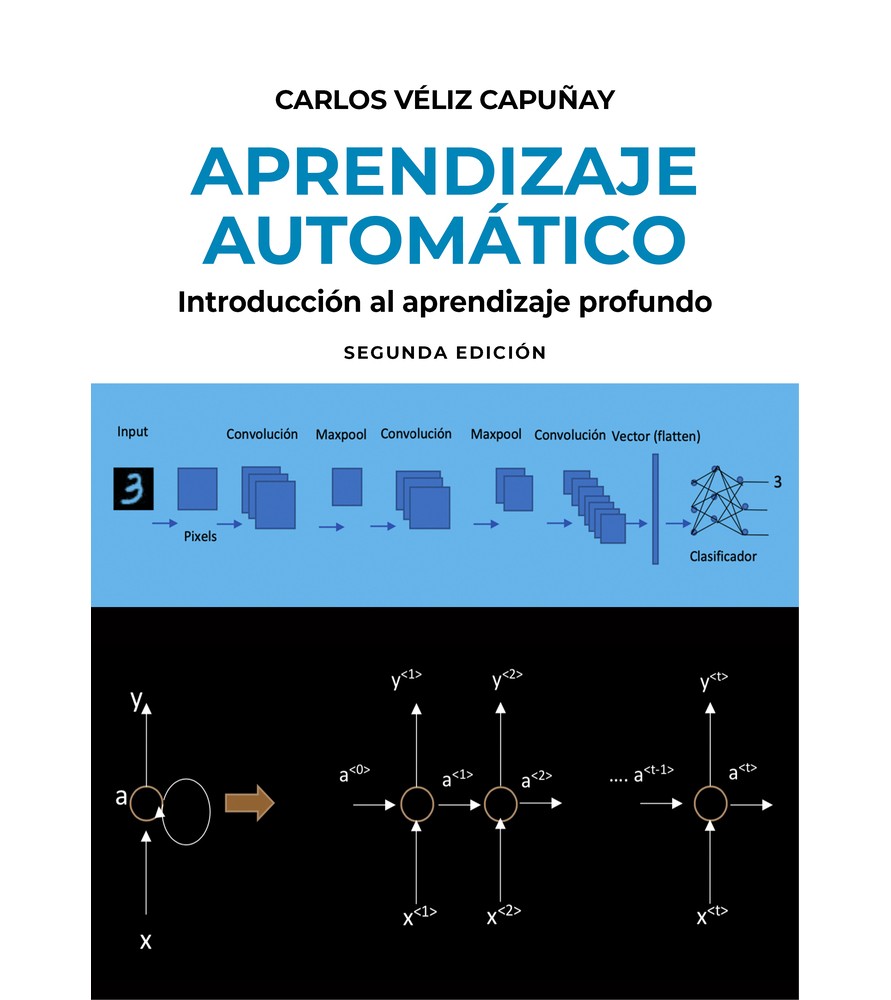
El aprendizaje automático, también conocido como machine learning en inglés, es un fascinante campo de estudio de la inteligencia artificial. Se ocupa del desarrollo de algoritmos y modelos que permiten a las computadoras aprender y tomar decisiones o hacer predicciones basadas en datos. Gracias a esta disciplina, las máquinas pueden adquirir conocimientos y habilidades sin ser programadas explícitamente, sino a través de la exposición a un conjunto de datos. Esto ha llevado a avances significativos en una amplia variedad de áreas, desde el análisis de datos hasta la robótica y la medicina.
Índice
Aprendizaje automático: definición y tipos
El aprendizaje automático es un subconjunto esencial de la inteligencia artificial, que se basa en la idea de que las máquinas pueden aprender a partir de datos y mejorar su rendimiento en tareas específicas. Los algoritmos de aprendizaje automático se pueden clasificar en diferentes tipos, entre ellos:
1. Aprendizaje supervisado: Este tipo de aprendizaje se basa en el uso de datos de entrenamiento etiquetados, es decir, en los que se conoce la respuesta correcta. El algoritmo aprende a través de la relación entre los atributos de los datos y las etiquetas correspondientes, y luego puede hacer predicciones o tomar decisiones en nuevos datos de prueba. Ejemplos de algoritmos supervisados incluyen la regresión lineal, la regresión logística y el árbol de decisión.
2. Aprendizaje no supervisado: En este caso, los datos de entrenamiento no están etiquetados con ninguna respuesta o clase. El algoritmo busca patrones ocultos o estructuras en los datos y agrupa los objetos o los describe de alguna manera útil. El aprendizaje no supervisado se utiliza comúnmente en la segmentación de datos, la detección de anomalías y la reducción de dimensionalidad. Algunos algoritmos no supervisados conocidos son el k-means, la agrupación jerárquica y las redes neuronales autoorganizadas.
3. Aprendizaje por refuerzo: En este tipo de aprendizaje, los algoritmos toman decisiones secuenciales en un entorno dinámico. El agente de aprendizaje recibe recompensas o castigos según sus acciones y tiene como objetivo maximizar la recompensa acumulada en el tiempo. Los ejemplos más conocidos de aprendizaje por refuerzo son los algoritmos de Q-learning y el de monte carlo.
Cada tipo de aprendizaje automático tiene sus propias características y aplicaciones, pero todos comparten el objetivo de permitir a las máquinas aprender y mejorar su rendimiento a partir de datos.
Algoritmos clave para principiantes
Para aquellos que recién se adentran en el campo del aprendizaje automático, existen algunos algoritmos clave que son especialmente adecuados para principiantes. Estos algoritmos son relativamente sencillos de entender y aplicar, y proporcionan una base sólida para comprender los conceptos fundamentales del aprendizaje automático. A continuación, se presentan dos algoritmos clave:
1. Regresión lineal: La regresión lineal es un algoritmo supervisado que se utiliza para predecir una variable continua en función de una o más variables independientes. El objetivo es encontrar la mejor línea recta que se ajuste a los datos. A través de este algoritmo, se puede entender cómo una variable dependiente varía en relación con una o más variables independientes. Es una herramienta muy utilizada en estadística y análisis de datos, y proporciona una base sólida para comprender otros algoritmos más avanzados.
2. Regresión logística: La regresión logística es otro algoritmo supervisado comúnmente utilizado, pero a diferencia de la regresión lineal, se utiliza para predecir una variable categórica binaria (por ejemplo, sí/no, verdadero/falso) en función de una o más variables independientes. El resultado de este algoritmo es una probabilidad, que se puede convertir en una clase específica utilizando un umbral predefinido. La regresión logística es útil en una amplia gama de aplicaciones, como la clasificación de correos electrónicos como spam o no spam, el diagnóstico médico y la detección de fraudes.
Estos son solo dos ejemplos de algoritmos clave en el aprendizaje automático para principiantes. Importante recordar que hay muchos otros algoritmos y técnicas que se pueden explorar a medida que se profundiza en el campo. Comprender estos algoritmos básicos puede sentar las bases para desarrollar habilidades más avanzadas en el ámbito del aprendizaje automático.
Desafíos éticos y de seguridad
A medida que el aprendizaje automático se ha vuelto más omnipresente en diversas industrias y sectores de la sociedad, han surgido preocupaciones sobre los desafíos éticos y de seguridad asociados con su aplicación. Estos desafíos plantean cuestiones importantes que deben abordarse para garantizar un uso responsable de los algoritmos de aprendizaje automático. A continuación, se exploran algunos de estos desafíos:
1. Sesgo algorítmico: Los algoritmos de aprendizaje automático pueden verse afectados por sesgos inherentes en los datos de entrenamiento utilizados para su desarrollo. Si los datos de entrenamiento contienen sesgos o discriminaciones sistémicas, los algoritmos pueden producir resultados sesgados o discriminatorios. Esto puede tener consecuencias negativas en la toma de decisiones automatizadas, como la contratación de personal o la concesión de créditos. El desafío ético radica en garantizar que los algoritmos sean imparciales y no contribuyan a la amplificación de sesgos existentes en la sociedad.
2. Privacidad y seguridad de los datos: El aprendizaje automático depende en gran medida de datos para entrenar y mejorar los algoritmos. Sin embargo, esto plantea preocupaciones en cuanto a la privacidad y seguridad de los datos. Es crucial garantizar que los datos utilizados en el proceso de aprendizaje automático sean obtenidos y utilizados de manera legal y ética, protegiendo la información personal sensible de los individuos. Además, los sistemas de aprendizaje automático deben ser seguros para evitar la manipulación malintencionada de los datos o el sabotaje de los algoritmos.
3. Responsabilidad y transparencia: A medida que los algoritmos de aprendizaje automático toman decisiones que pueden tener un impacto significativo en la vida de las personas, es fundamental establecer mecanismos claros de responsabilidad y transparencia. Los individuos deben tener la capacidad de comprender cómo funcionan los algoritmos, qué datos se utilizan para tomar decisiones y qué garantías existen para evitar resultados injustos o perjudiciales. Esto implica la necesidad de una supervisión adecuada, la documentación de los procesos de toma de decisiones y la rendición de cuentas por los resultados producidos por los algoritmos.
Estos desafíos éticos y de seguridad no son exhaustivos, pero destacan algunas de las preocupaciones más importantes relacionadas con la aplicación del aprendizaje automático. A medida que la tecnología avanza, es fundamental abordar estos desafíos de manera proactiva y colaborativa para garantizar un uso responsable y beneficioso de los algoritmos de aprendizaje automático.
Aplicaciones en diferentes ámbitos
El aprendizaje automático se ha convertido en una herramienta valiosa en una amplia variedad de ámbitos y sectores. Su capacidad para analizar grandes cantidades de datos y obtener información útil ha llevado a su aplicación en numerosas áreas. A continuación, se presentan algunas de las aplicaciones más destacadas del aprendizaje automático:
1. Medicina: El aprendizaje automático se utiliza en la medicina para diagnosticar enfermedades, predecir riesgos y ayudar en la toma de decisiones clínicas. Los algoritmos pueden analizar datos médicos, como imágenes de resonancia magnética y registros médicos electrónicos, para identificar patrones y predecir resultados clínicos. Además, el aprendizaje automático se aplica en la genómica para analizar el ADN y encontrar variantes genéticas relacionadas con enfermedades.
2. Finanzas: En el sector financiero, el aprendizaje automático se utiliza para analizar grandes volúmenes de datos, identificar patrones y tomar decisiones de inversión más precisas. Los algoritmos pueden analizar datos históricos del mercado, noticias financieras y otros factores para predecir el rendimiento de las acciones y realizar operaciones automatizadas. Además, el aprendizaje automático se aplica en la detección de fraudes financieros, identificando patrones sospechosos y alertando sobre posibles transacciones fraudulentas.
3. Retail y marketing: Las empresas utilizan el aprendizaje automático para analizar datos de compra y comportamiento del consumidor, lo que les permite mejorar la personalización y la segmentación de sus campañas de marketing. Los algoritmos pueden predecir las preferencias de los clientes, recomendar productos relevantes y optimizar los precios. Además, el aprendizaje automático se aplica en la gestión de inventario, ayudando a predecir la demanda y evitar la escasez o el exceso de productos.
4. Transporte y logística: La industria del transporte se beneficia del aprendizaje automático al optimizar rutas, predecir tiempos de entrega y evitar retrasos. Los algoritmos pueden analizar datos en tiempo real, como el tráfico y las condiciones climáticas, para tomar decisiones de enrutamiento más eficientes. Además, el aprendizaje automático se aplica en la gestión de flotas, ayudando a realizar un mantenimiento predictivo y a optimizar la eficiencia de los vehículos.
Estos son solo algunos ejemplos de las aplicaciones del aprendizaje automático en diferentes ámbitos. Su capacidad para procesar grandes volúmenes de datos y extraer información valiosa lo convierte en una herramienta potente en la era de la información y la tecnología avanzada.
Alba Renai: La Influencer Virtual que Despierta Misterio y Debate
¿Asistente virtual de IA más innovador: Bing Chat?

Descubre Microsoft Copilot: chat de inteligencia artificial
Articulos relacionados